📝
Cloud Strategy16 Apr 2026
Azure AI Foundry changes that matter for enterprise teams
Enterprise teams need clear guidance on rollout detail, governance impact, and the practical next step.
By Leon GodwinRead more

Stay updated with the latest AI trends, strategies, and success stories.
Enterprise teams need clear guidance on rollout detail, governance impact, and the practical next step.

Most organisations do not have a data security tooling problem.

Most organisations do not struggle to detect risky behaviour. They struggle to understand it quickly enough to act.

Most security teams are not drowning in risk. They are drowning in triage.
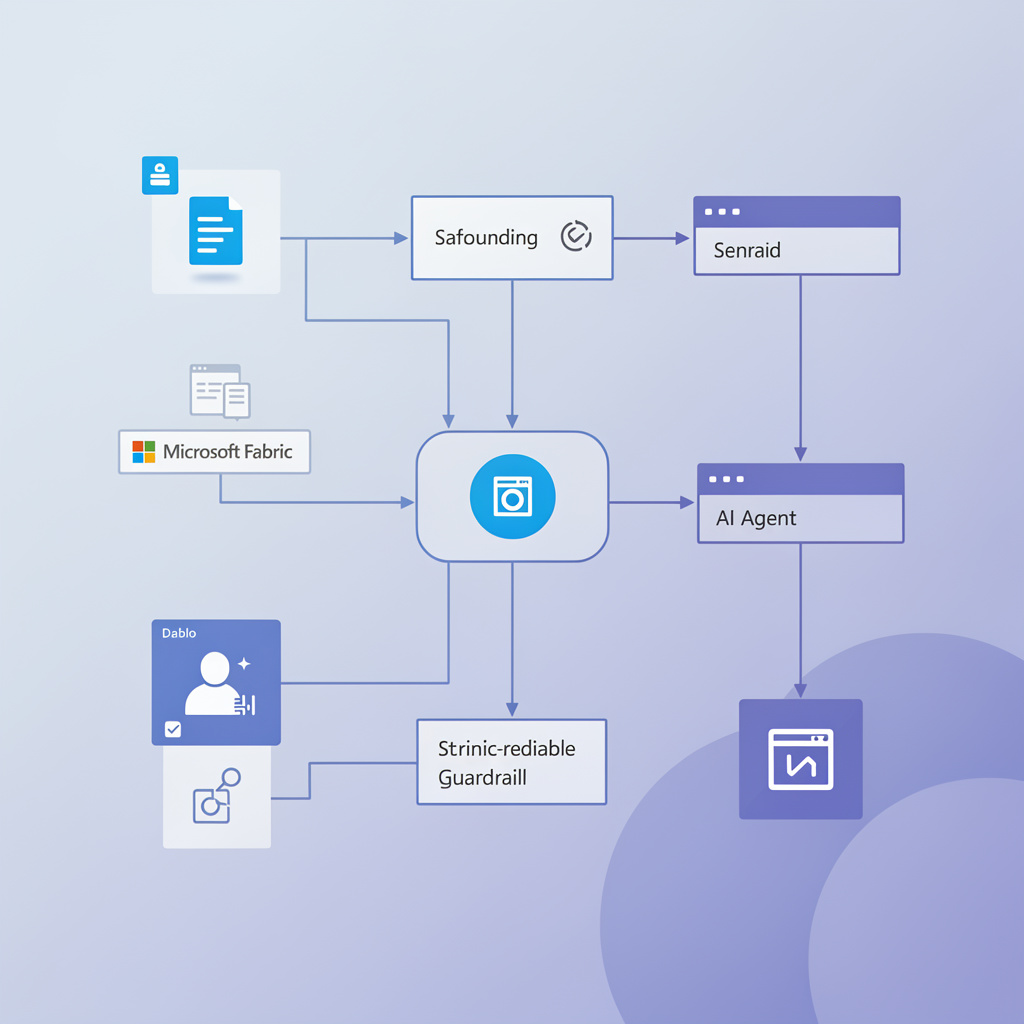
A lot of organisations talk confidently about responsible AI, data governance, and secure analytics. Then you look at the actual implementation and realise the controls are still built for humans, not machines.
A lot of enterprise data platforms still expect modern engineering teams to work like button-clicking operators.
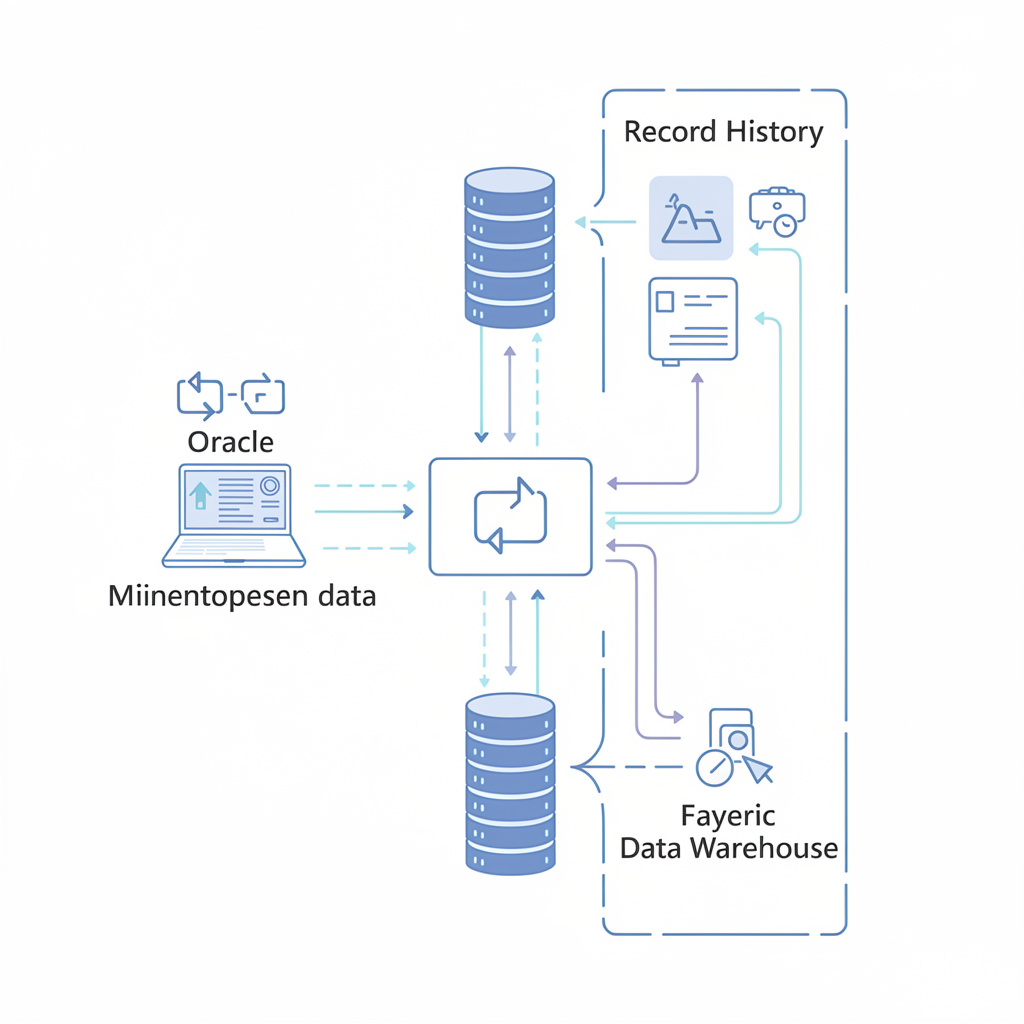
Most AI roadmaps still underestimate one brutally practical problem: getting trustworthy operational data out of the systems that matter, fast enough, and with enough history, to make downstream analytics and AI useful.
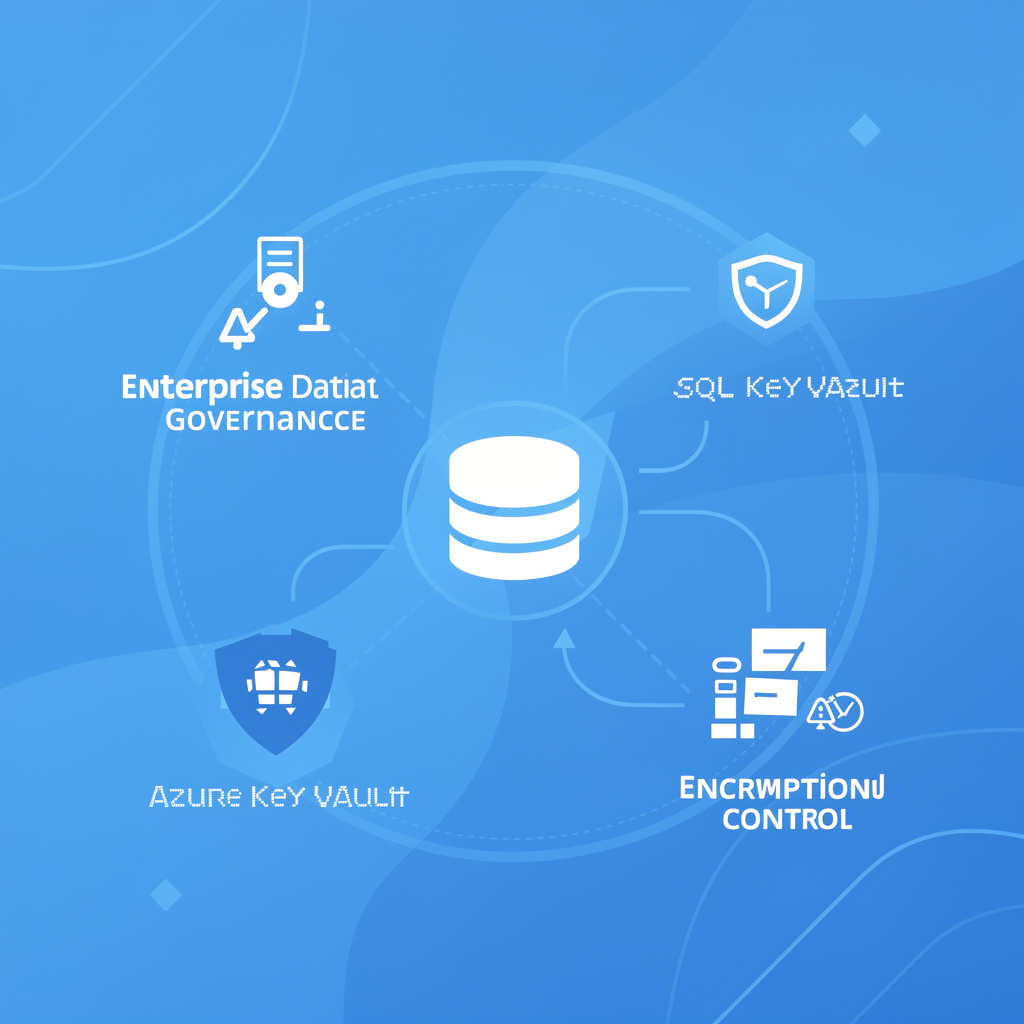
For a lot of teams, encryption at rest gets treated as a tick-box. If the platform says data is encrypted, the conversation ends there.

Microsoft’s new compute auto-scaling choices for SQL databases in Microsoft Fabric look, at first glance, like another incremental platform tweak. More elasticity. More tuning. More options.
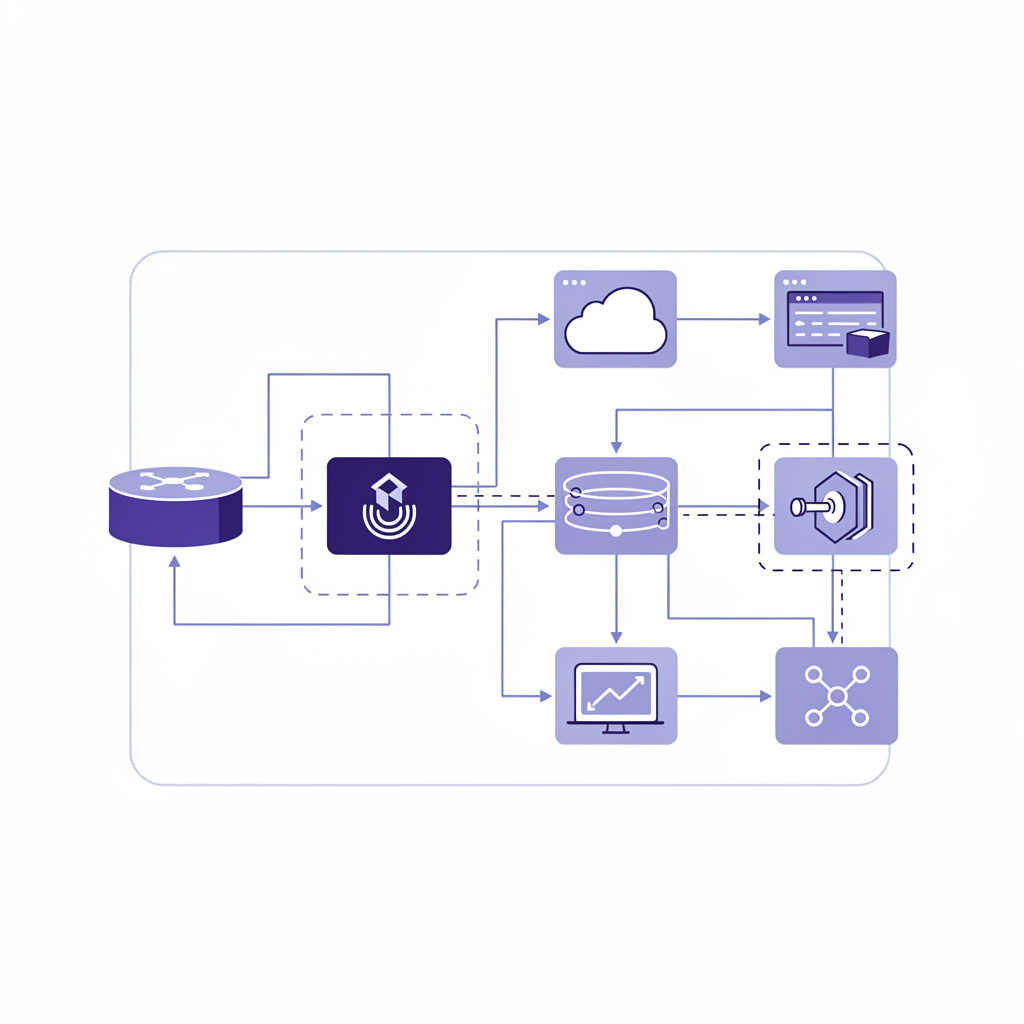
Most organisations do not have a data orchestration problem. They have a hand-off problem.

Most database migration projects do not fail because the tooling is missing. They fail because the target operating model is unclear.
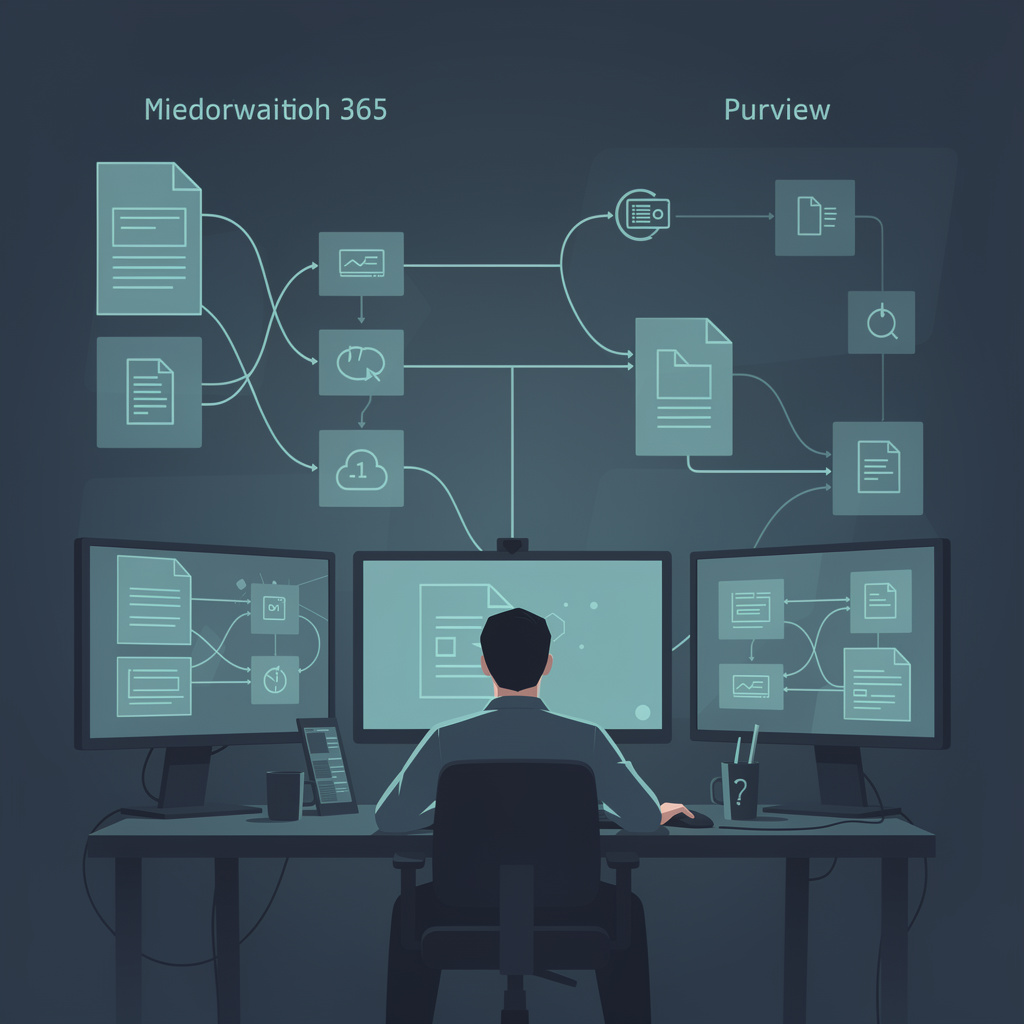
Most data security incidents do not fail because we lack alerts. They fail because we cannot turn the signal into a decision fast enough.

Most organisations do not have a database performance problem. They have a database predictability problem.
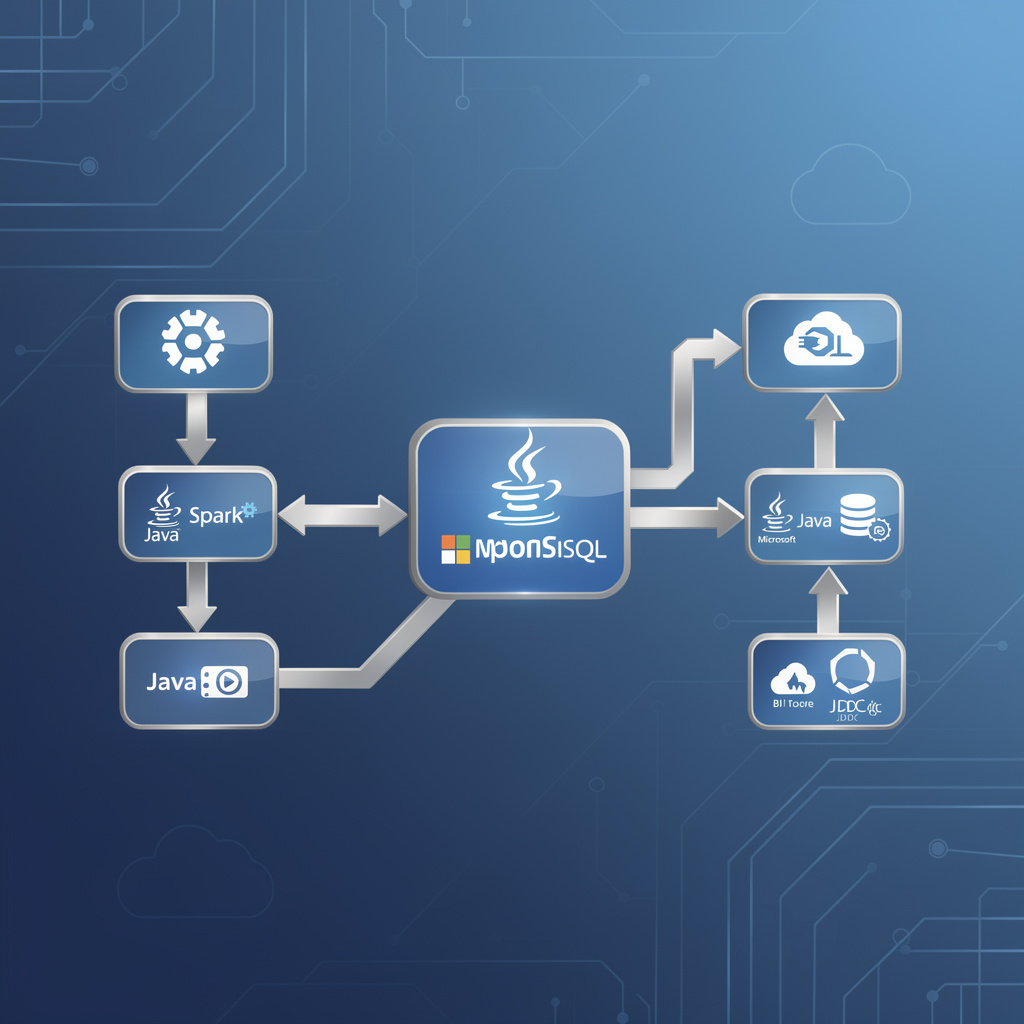
A lot of AI conversations still skip the part where enterprise systems have to connect cleanly to the data platform underneath.
One of the hardest problems in security is not the absence of signals. It is the overproduction of weak ones.
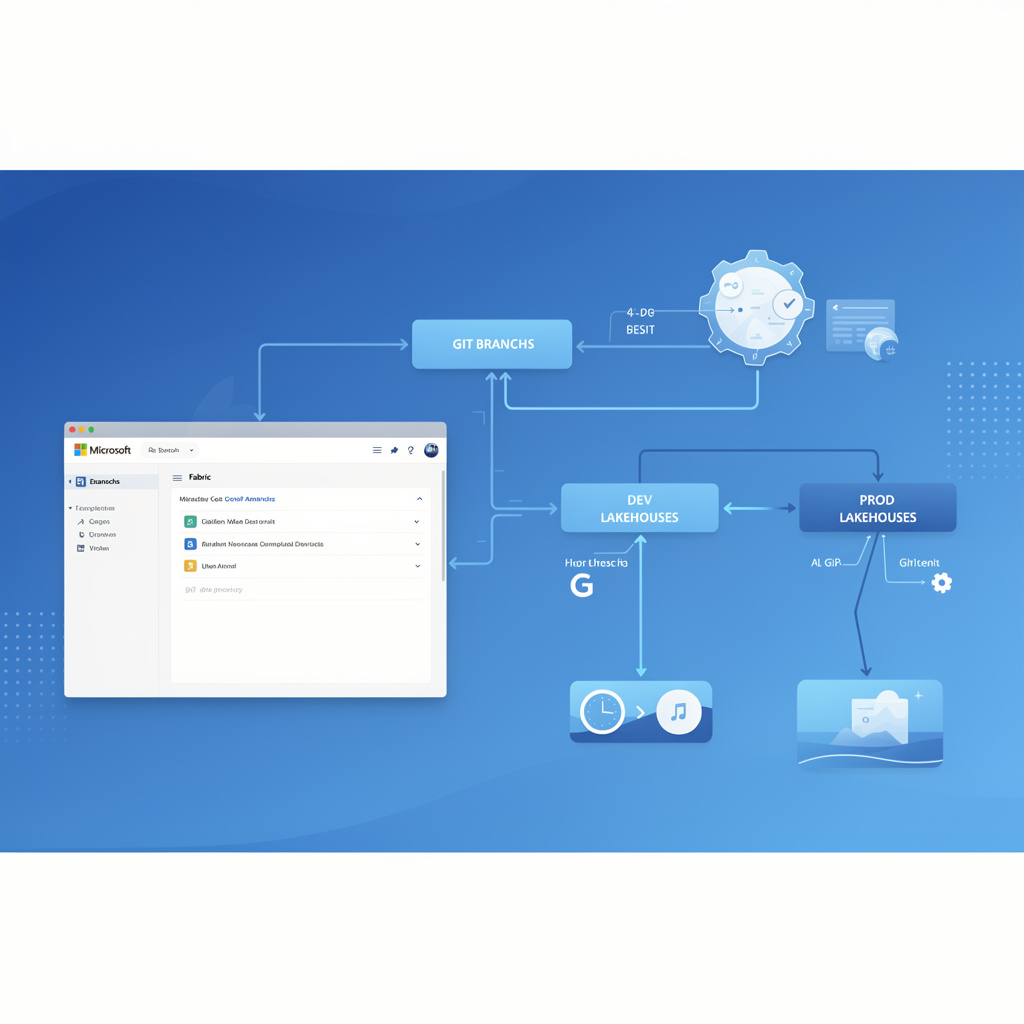
Most teams think Git adoption in analytics fails because people resist engineering discipline. That is not usually the real issue.
A lot of AI conversations still skip the part where enterprise systems have to connect cleanly to the data platform underneath.
The next wave of enterprise AI will not be won by whoever writes the cleverest prompt. It will be won by organisations that give agents access to trusted operational context.

That is the real significance of Microsoft’s latest Fabric IQ Ontology update.

Every team building AI agents hits the same wall. The proof of concept works beautifully. The coordinator routes to the right specialist, the tools return sensible answers, and the demo gets applause. Then someone asks: "How do we know the agent did the right thing?"

That is the real significance of Microsoft’s latest Fabric IQ Ontology update.

Every enterprise team building AI agents has hit the same wall. The prototype works brilliantly in a demo. Then you deploy it to production, hand it a 15-step workflow, and somewhere around step 9 it loses the plot. Instructions get fuzzy. Tools don't fire. Context drifts. You end up babysitting the

That is the real significance of Microsoft’s latest Fabric IQ Ontology update.

Most organisations talking about agentic AI are still focused on what the model can do.
Most enterprise data platforms have the same blind spot. They're brilliant at storing data, transforming it, visualising it. But when you ask "what should happen when this metric crosses a threshold?", the answer usually involves a different team, a different tool, and a ticket that sits in a queue
Every enterprise team building with large language models has hit the same wall. You load a codebase, a contract archive, or a month's worth of agent session logs — and the model runs out of context. So you chunk. You summarise. You build elaborate retrieval pipelines to feed the model pieces of wha
Most organisations I speak with have built an AI agent. A chatbot for internal IT queries, a document summariser, maybe a customer FAQ bot. They've proved the concept works.
Every team building AI agents hits the same wall. The proof of concept works beautifully. The coordinator routes to the right specialist, the tools return sensible answers, and the demo gets applause. Then someone asks: "How do we know the agent did the right thing?"
CI/CD pipelines are the most trusted part of your software supply chain. They build your code, run your tests, and deploy to production. And in most organisations, they run with elevated permissions that nobody has audited since the workflow was first committed.
Most enterprise teams I talk to have the same story about open models. They love the flexibility. They love the control. They love not being locked into a single provider's pricing and roadmap. And then they try to run open models in production and hit a wall.
Every organisation that uses Microsoft Fabric, Power BI, or Excel has Power Query scripts. Thousands of them. M language transformations that clean, reshape, and prepare data across the business. The problem? Those scripts have always been trapped inside interactive tools and scheduled dataflow refr
Every data engineer running a medallion architecture in Fabric has the same conversation at some point: "Why am I spending more time managing notebook schedules than writing actual transformations?"
Ask anyone building AI agents what their biggest pain point is, and you'll hear two things: tool orchestration and memory. We've made decent progress on the first. The second is still mostly unsolved.
Here's a pattern I see constantly with enterprise customers: someone builds a proof of concept that uses an LLM to pull structured data from free text. It works brilliantly in a notebook. Then they try to put it in a pipeline, and everything falls apart.
Ask anyone building AI agents what their biggest pain point is, and you'll hear two things: tool orchestration and memory. We've made decent progress on the first. The second is still mostly unsolved.
Here's a pattern I see constantly with enterprise customers: someone builds a proof of concept that uses an LLM to pull structured data from free text. It works brilliantly in a notebook. Then they try to put it in a pipeline, and everything falls apart.
The Model Context Protocol has gone from "interesting spec" to "everyone's building with it" remarkably quickly. MCP gives AI agents a standardised way to discover and call external tools — browse a database, query an API, interact with a file system — without hardcoding every integration. It's mode
Data teams spend most of their time preparing data, not analysing it. That's not a controversial statement — it's the consistent reality across every organisation I've worked with. The ratio is usually somewhere around 80/20: eighty per cent of the effort goes into connecting, cleaning, and transfor
Every enterprise IT leader I speak to is having the same conversation with their board: "We're spending on Copilot. Where's the ROI?" And right behind that question sits a harder one: "We have agents everywhere now. Who's governing them?"
There's a stubborn assumption in the AI world: if you want a model that can reason about images and text together, you need something enormous. More parameters, more training tokens, more GPUs. The result is models that are impressively capable but impractical for most real-world deployments — too s
If you've been building AI agents on the Microsoft stack, the last 18 months have felt like choosing between two good but incompatible paths. Semantic Kernel gave you enterprise-grade state management, middleware pipelines, and production telemetry. AutoGen gave you flexible multi-agent patterns and
Monthly Fabric feature summaries are dense. There's always a long list of incremental improvements, and the real question for most teams is: which of these actually matter for our workloads? February 2026 brings over 30 updates across the platform — from notebook encryption to Data Factory performan
If you run Spark workloads on Microsoft Fabric, you've probably noticed the same pattern I see with customers: data volumes keep growing, refresh windows keep shrinking, and the Spark jobs that ran fine six months ago now need constant tuning. Cluster scaling becomes the default answer, which means
Every conversation about enterprise AI eventually hits the same wall: "What does this cost at scale?"
Every organisation has the same data problem. Raw SQL sits in databases, data lakes, and warehouses. Getting it from "stored" to "useful" means building ETL pipelines — mapping transformations, writing SQL joins, configuring data flows. It's skilled work that takes hours, sometimes days.
You deploy Microsoft Copilot to help your team work faster. Summarise documents, answer questions, pull up files. Standard productivity play.
Every AI demo I see starts with "just spin up a vector database, add a search index, deploy an embedding service, configure an orchestrator..." and by the time you've provisioned the infrastructure, you've spent more on setup than the prototype is worth.
Here's a tension that comes up in almost every conversation I have with public sector and regulated industry IT leaders: they want AI, but they can't send data to the cloud. Not won't — can't. Regulatory requirements, classification levels, or operational risk profiles simply don't allow it.
Every IT leader I speak to has the same frustration with Copilot: it's good at drafts but terrible at follow-through. Ask it to summarise a meeting and you'll get a decent summary. Ask it to then reschedule three conflicts, prepare the briefing deck, pull the latest numbers from Excel, and email the
Reasoning models are the new frontier. Not the general-purpose chatbot variety — the kind that work through multi-step logic, decompose scientific problems, and generate code with genuine chain-of-thought. The catch? Running them in production has meant either paying frontier-model prices or self-ho
Every enterprise conversation about AI agents eventually hits the same wall. Someone asks: "But who's managing all these agents?"
If you've been following the multimodal AI space, you've noticed the arms race. Models getting bigger. Token counts climbing. Inference costs rising. And for what? Many production workloads don't need a 400-billion-parameter model to read a receipt or answer a question about a chart.
There's a pattern in enterprise AI adoption that plays out the same way every time. Leadership buys the licences. A few early adopters figure it out. Everyone else opens the tool once, doesn't quite know what to ask it, and quietly goes back to Stack Overflow.
Every conversation about enterprise AI eventually hits the same wall: "What does this cost at scale?"
You assign an issue before lunch. By the time you're back, there's a pull request waiting. Not a rough draft — a reviewed, security-scanned, ready-for-your-eyes pull request.
If you've spent any time with GPT-5.2 Instant, you'll know the feeling. You ask a straightforward question and get hit with a wall of caveats, disclaimers, and unsolicited life advice before the model gets around to answering. The community called it "cringe" — and they weren't wrong.
There's a persistent assumption in enterprise AI: if you want a model that reasons well over visual content, you need a frontier-scale model with frontier-scale costs. Phi-4-Reasoning-Vision-15B challenges that directly. It's a 15-billion parameter model that combines high-resolution visual percepti
Every enterprise team building AI agents has hit the same wall. The prototype works brilliantly in a demo. Then you deploy it to production, hand it a 15-step workflow, and somewhere around step 9 it loses the plot. Instructions get fuzzy. Tools don't fire. Context drifts. You end up babysitting the



Microsoft is proposing a fundamental shift from dashboard-driven cloud ops to agent-driven cloud ops. Six Azure Copilot agents now cover the full lifecycle. Here is what that actually means for your organisation.
The Azure portal Sentinel experience retires in 2026. A practical five-step framework for migrating to the Defender portal without breaking your SOC.
Most organisations build Copilot Studio agents like chatbot experiments. The VS Code extension GA changes everything about agent governance.
Your Azure analytics stack evolved rather than was designed. Here is a practical 5-stage framework for migrating to Microsoft Fabric without breaking what works.
Exploring Cost Savings vs Hype
Optimising logistics with AI
Driving data consistency with a simple AI data pipeline
Exploring AI and automation to optimise business processes
RAG or Retrieval Augmented Generation in the legal industry to accelerate insights
AI and Data Loss Provention
Deciding if you should build or buy your AI solutions is a key strategic decision. Here we explore the areas of consideration.
Fear is in the top 3 biggest blocker to successful AI adoption. We explore simple steps to help overcome this fear.
The conversation around AI agents has shifted from theory to urgency, with promises to revolutionize customer service, IT, finance, and marketing by automating complex workflows and enabling human teams to focus on strategy. However, many businesses overlook critical truths beneath the hype. Leaders often fixate on platform features and cost savings, missing deeper operational and strategic changes required for success. This article uncovers the most impactful and surprising realities of deploying AI agents—insights that determine whether an initiative becomes a costly failure or a transformative investment delivering exceptional returns. Understanding these truths is essential for sustainable competitive advantage.
Get the latest AI insights and tips delivered directly to your inbox.