
The data integration problem most AI strategies ignore
Most AI roadmaps still underestimate one brutally practical problem: getting trustworthy operational data out of the systems that matter, fast enough, and with enough history, to make downstream analytics and AI useful.
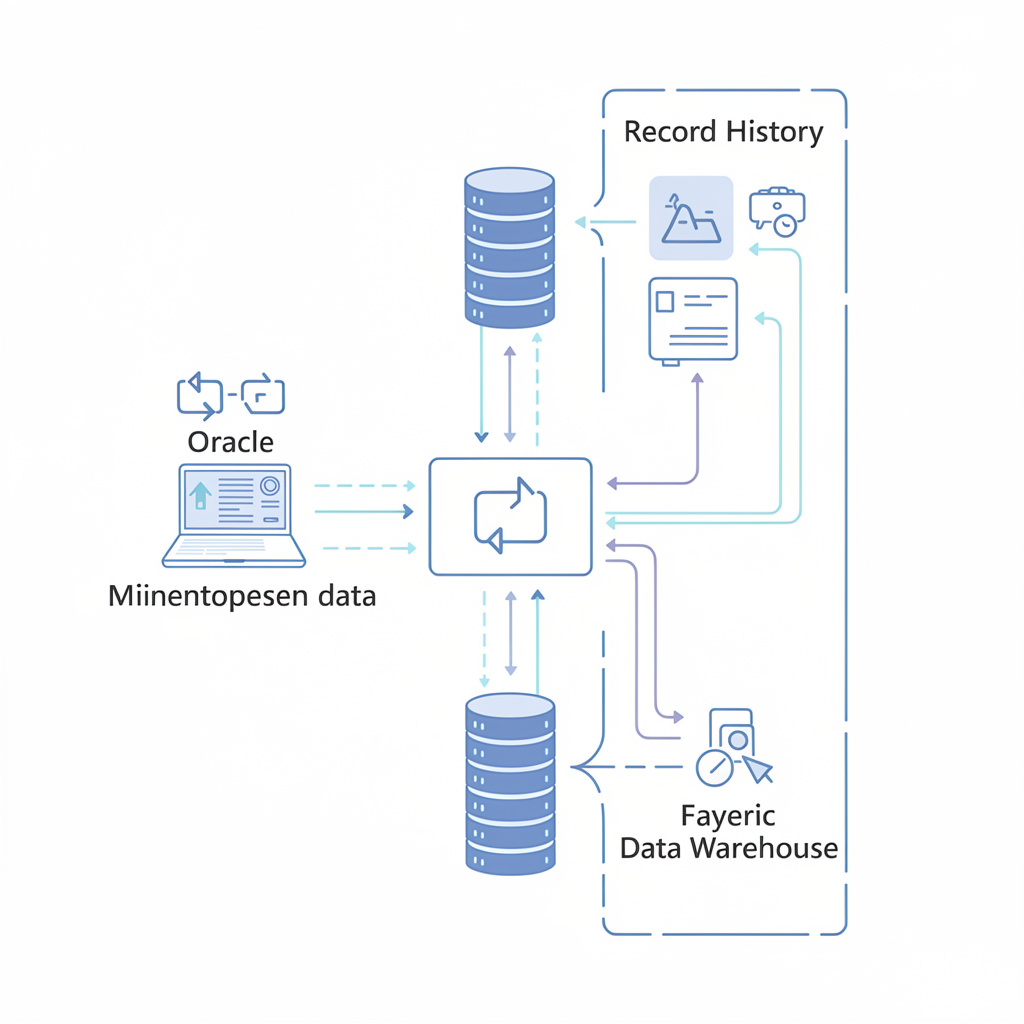
That is why Microsoft Fabric’s latest Copy job update matters more than the headline suggests. On paper, this is a product update about richer change data capture, Oracle as a CDC source, Fabric Data Warehouse as a sink, and built-in SCD Type 2 support. In practice, it is another sign that Microsoft understands where enterprise AI projects actually stall: not in the model demo, but in the plumbing between old line-of-business systems and the data platform teams want to standardise on.
I see this with customers all the time. The ambition is usually clear enough. Build a better data estate. Improve reporting latency. Create a stronger foundation for copilots, agents, and decision support. But then the hard reality shows up: critical business data still lives in Oracle, SQL Server, SAP-adjacent estates, and a mix of cloud and on-premises platforms that were never designed with modern AI pipelines in mind.
And that is where many projects lose momentum.
The challenge
The challenge is not simply copying data from one place to another. Enterprises need to move changing data reliably, preserve historical context, and do it without creating another layer of brittle custom engineering.
If your sales orders, customer records, inventory changes, or finance movements are sitting inside Oracle, it is not enough to run occasional full loads and hope for the best. Full loads are expensive, slow, and operationally clumsy. They also make it harder to answer important questions later. When did this customer segment change? When was this product classification updated? Which version of the record existed when a decision was made?
That is why CDC matters. Done properly, it lets teams capture inserts, updates, and deletes as they happen, rather than treating the source system like a static export file.
And that is why SCD Type 2 matters as well. It is not glamorous, but it is essential when organisations need a proper historical trail rather than a constantly overwritten snapshot. If you want trustworthy analytics, cleaner governance, and any realistic chance of explainable AI over enterprise data, keeping change history is foundational.
The problem is that many organisations still stitch this together with bespoke pipelines, custom transformations, extra orchestration, and too much tribal knowledge. It works. Until it doesn’t.
What’s changed in Fabric
Microsoft’s update to Copy job in Fabric Data Factory adds a more useful combination of capabilities than it might first appear.
First, Oracle is now supported as a CDC source in Copy job. That matters because Oracle remains deeply embedded in many enterprise estates, especially in finance, manufacturing, logistics, and core business applications. If Fabric is going to become a real control plane for enterprise data and AI, it cannot just work nicely with modern Microsoft-native sources. It has to meet organisations where they already are.
Second, Fabric Data Warehouse is now supported as a destination in these CDC scenarios. That tightens the path from operational systems into an analytics-ready platform inside Fabric, without forcing teams to design a separate landing pattern before they can create value.
Third, Copy job includes built-in support for SCD Type 2 as a write method. That is a bigger deal than many announcements make it sound. Historically, teams often had to build custom logic to maintain historical versions of records. That usually meant more code, more maintenance, more testing, and more room for governance drift. Bringing SCD Type 2 into the product flow reduces that overhead.
The result is not magic. But it is progress in the right place.
What Microsoft is really doing here is making a common enterprise integration pattern easier to adopt in a governed, repeatable way. Less custom glue. Less pipeline sprawl. Fewer one-off workarounds.
Why this matters for organisations investing in AI
Here is the practical point: AI adoption is rarely blocked by model access alone. It is blocked by data readiness.
If your business wants to build internal copilots, retrieval systems, forecasting tools, agentic workflows, or decision support applications, those systems need access to current and trusted business data. They also need enough historical structure to interpret context properly.
A customer support assistant is more useful when it can see how account status changed over time.
A planning model is more useful when it can work from near-current operational data instead of yesterday’s export.
A governance team is more confident when they know how records were landed, transformed, and versioned.
This is why I would frame this update as an AI-enablement story, not just a data engineering story. Better CDC support and simpler historical loading patterns do not grab attention like a frontier model release, but they solve the kind of problem that determines whether AI projects can survive contact with the enterprise.
That is the non-obvious angle senior IT leaders should care about.
The organisations getting the most value from AI are not always the ones with the loudest innovation narrative. Often, they are the ones that have reduced friction between operational systems and governed analytical platforms.
The architectural implications
There are a few important caveats here.
First, preview features are still preview features. Teams should validate performance, connector behaviour, operational limits, and support boundaries before betting a production-critical workflow on them.
Second, Oracle CDC is helpful, but it does not remove the need for good architecture. Teams still need to think about data domains, ownership, destination design, retention, and how change history will be used downstream.
Third, SCD Type 2 support simplifies implementation, but it does not simplify governance by itself. If an organisation has weak definitions for customer, product, supplier, or policy entities, automating history only preserves confusion more efficiently.
And fourth, this does not replace the need for platform discipline. You still need naming standards, monitoring, security controls, testing, and an operating model for who owns the pipelines once they are live.
That matters because many estates do not fail through lack of features. They fail through lack of consistency.
A real-world way to think about it
Imagine a retail or manufacturing business running important operational processes in Oracle while trying to consolidate analytics and AI workloads into Fabric.
The old pattern might involve batch exports, custom ETL logic, staging tables, and hand-built history management. Every change request adds more complexity. Every schema shift becomes a mini-project.
The newer Fabric pattern is cleaner: capture change data from Oracle, land it in Fabric Data Warehouse, preserve record history with SCD Type 2, and make that data available to analytics and AI workloads from a more consistent platform.
That does not eliminate all effort. But it shortens the path from source system change to business insight.
And in enterprise terms, shortening that path is often where value appears.
Getting started
If you are already using Microsoft Fabric, this is worth testing in a contained scenario.
Start with a business dataset where latency and history both matter. Customer master is a good example. Product data is another. Order or inventory changes can also work well.
Then validate four things.
First, can you capture changes from the source with the reliability and granularity you need?
Second, does the destination model in Fabric Data Warehouse support the reporting and AI scenarios you actually care about?
Third, are the SCD Type 2 outputs understandable to the teams who will consume them?
And fourth, do you have the governance discipline to operationalise this beyond a proof of concept?
I would also recommend reading the Microsoft documentation on CDC in Copy job alongside the Fabric blog announcement, rather than relying on the marketing summary alone. The feature story is useful. The operational details are where the real design decisions sit.
What this means
My view is simple: this is the kind of update that serious enterprise teams should pay attention to, because it improves the boring middle of transformation.
And the boring middle is where most value is won or lost.
The practical business case is not “we can now move Oracle data into Fabric”. The practical business case is that Microsoft is making it easier to turn changing operational data into governed analytical history without as much custom engineering. That is good for reporting. It is good for platform consistency. And yes, it is good for AI adoption, because better data movement and cleaner history make downstream AI systems more useful and less fragile.
If you are leading data or AI strategy, this is the right question to ask: are we still spending too much effort moving and versioning data manually when the platform can now do more of that work for us?
That is the conversation worth having.
Leon Godwin, Principal Cloud Evangelist at Cloud Direct